Alignment of ANN Language Models with Humans After a Developmentally Realistic Amount of Training
Abstract
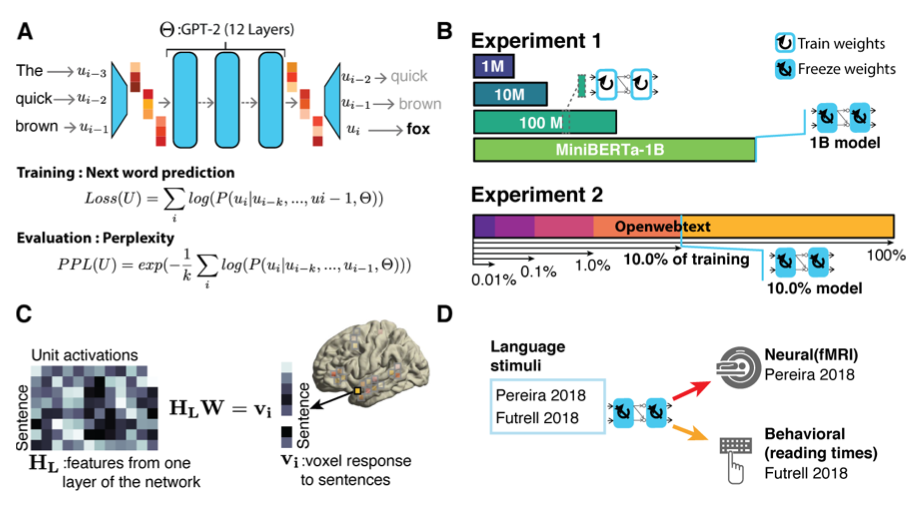
Artificial neural networks (ANN) have emerged as computationally plausible models of human language processing. A major criticism of these models is that the amount of training data they receive far exceeds that of humans. Here, we use two complementary approaches to ask how the models ability to capture human neural and behavioral responses to language is affected by the amount of training data. First, we evaluate GPT-2 models trained on 1 million, 10 million, 100 million, or 1 billion tokens against a neural (fMRI) and a behavioral (reading times) benchmark. Because children are exposed to approximately 100 million words during the first 10 years of life, we consider the 100-million-token model developmentally plausible. Second, we test the performance of a GPT-2 model that is trained on a 9-billion dataset to reach state-of-the-art next-word prediction performance against the same human benchmarks at different stages during training. Across both approaches, we find that (i) the models trained on a developmentally plausible amount of data already achieve near-maximal performance in capturing neural and behavioral responses to language. Further, (ii) lower perplexity - a measure of next-word prediction performance - is associated with stronger alignment with the human benchmarks, suggesting that models that achieve sufficiently high next-word prediction performance also acquire human-like representations of the linguistic input. In tandem, these findings establish that although some training is necessary for the models ability to predict human responses to language, a developmentally realistic amount of training (~100 million tokens) may suffice.